Schon vor einiger Zeit hat Tobi gemeint, dass es doch eine ganz coole Idee wäre, das Blog webguys.de unter GitHub zu pflegen und so anderen zu erlauben, neue Blog-Beiträge per Pull-Request zu erstellen. Richtig Entwickler-Like eben. Wer seine Präsentation schon im git hat, der sollte auch seine komplette Website in einem Repo verwalten. Oder?
Nachdem ich dann vor einiger Zeit meinen Beitrag zu GitHub Pages geschrieben habe, hatte ich mich etwas näher mit Jekyll auseinander gesetzt. Dabei ist mir aufgefallen, dass genau hier wahrscheinlich die Lösung für die Idee von Tobi liegt. In diesem Beitrag möchte ich daher einmal Dokumentieren, wie gut oder schlecht das Ganze klappt. Und ob am Ende überhaupt etwas brauchbares heraus kommt. Scheinbar ist die Technologie auf dem aufsteigenden Ast – immerhin setzt Magento 2 mit der Dokumentation ebenfalls auf Jekyll. Auch hier kann man jede einzelne Seite mit einem Fork / Pull-Request bearbeiten.
Leider hat Tobi aber momentan nicht so die Lust sich in Jekyll einzuarbeiten und ist von der Technologie noch nicht so überzeugt – daher muss ich das wohl mit meinem Hausautomatisierungsportal machen. Auch nicht schlimm! Ist auch erstmal kleiner. Außerdem hat die Seite noch nicht so viele Kommentare… Die müsste man nämlich extern auslagern (z.B. zu Disqus).
Die Schwierigkeit besteht sicher darin, alles mit der gleichen Linkstruktur zu übernehmen um keine Einbußen bei Google zu haben. Ich bin gespannt – starten wir!
Grundgerüst
Im ersten Schritt habe ich einfach „View Page Source“ aufgerufen und alles in ein entsprechendes Template kopiert. Das ist natürlich auch DIE Chance, das Ganze HTML-Zeug gleich einmal aufzuräumen! Dabei fällt einem sicher das ein oder andere Verbesserungspotenzial auf! Die wenigen Bilder auf der Seite lade ich erst einmal herunter und übernehme soviel wie nur geht. Am Ende darf nirgendwo mehr die Domain auftauchen – gar nicht so einfach und erstmal eine Menge Arbeit! Puh…
Oder doch ganz anders… Also habe ich mir nach den ersten Schritten ein Bootstrap 3 Template gekauft und baue nun da drauf auf. Fühlt sich auch sauberer an und mit einem neuen Design geht auch gleich alles viel einfacher von der Hand (Soviel zur Theorie…). Das neue Theme habe ich dann erst einmal in seine Bestandteile zerlegt und ein erstes Layout mit den entsprechenden Includes zusammengeschustert.

So muss man nicht alles doppelt schreiben und kann die einzelnen Bestandteile immer wieder verwenden. Gerade der Header mit Logo, Navigation, etc. und der Footer sehen schließlich auf allen Seiten gleich aus. So hat man verschiedene Bausteine und kann diese zentral bearbeiten. Änderungen über die komplette Seite sind dabei also nach wie vor sehr einfach. Die Zeit, die man hier investiert, spart man am Ende auf jeden Fall. Eine saubere Struktur macht einem das Leben schonmal viel einfacher! Und gerade in Software-Projekten lege ich sehr viel Wert auf Ordnung, Wiederverwendbarkeit und Struktur.
Mit den Includes ist es mir dann relativ leicht gefallen, die folgenden Layouts zu erstellen. Ein Layout ist dabei die „fertige“ Seite, welche mit Daten gefüttert wird. Welches Layout genutzt werden soll, legt man im Kopf der einzelnen Seiten später fest.
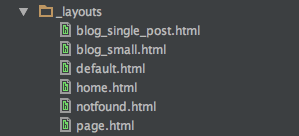
Dennoch müssen die alten Links ja weiter bestehen bleiben. Daher erstmal die ganzen Daten aus WordPress importieren.
Daten-Import
Um die Datenübernahme zu testen, installiere ich erstmal jekyll-import.
gem install jekyll-import
Der Importer selbst versteht verdammt viele Quellen:
- Behance
- Blogger
- CSV
- Drupal 6
- Drupal 7
- EasyBlog
- Enki
- Ghost
- Google Reader
- Joomla
- Jrnl
- Marley
- Mephisto
- Movable Type
- Posterous
- RSS
- S9Y
- Textpattern
- Third-party
- Tumblr
- Typo
- WordPress
- WordPress.com
WordPress ist natürlich auch dabei. Das führt man wie folgt aus:
ruby -rubygems -e 'require "jekyll-import";
JekyllImport::Importers::WordPress.run({
"dbname" => "",
"user" => "",
"password" => "",
"host" => "localhost",
"socket" => "",
"table_prefix" => "wp_",
"site_prefix" => "",
"clean_entities" => true,
"comments" => true,
"categories" => true,
"tags" => true,
"more_excerpt" => true,
"more_anchor" => true,
"extension" => "html",
"status" => ["publish"]
})'
Wie man sieht, ist eine Datenbankverbindung erforderlich. Also entweder einen Dump ziehen, oder (falls erlaubt) die Datenbank von außen kontaktieren. Ich hoffe einmal mal, dass hier keine Schreibvorgänge vorgenommen werden, sondern nur gelesen wird. Aber das sollte passen!
Direkt eine Fehlermeldung:
Whoops! Looks like you need to install 'sequel' before you can use this importer.
Naja, leicht zu beheben:
gem install sequel gem install mysql2 gem install unidecode gem install htmlentities
Stand ja auch schon in der Dokumentation, dass die einzelnen Importer eventuell weitere Dependencies brauchen, die nicht explizit mit angegeben wurden, um das Paket nicht unnötig aufzublähen.
Danach hat man in _posts jede Menge html-Dateien rumfliegen. So weit, so gut! Also erstmal aufräumen. Außerdem stelle ich die Dateiendung auf Markdown um und entferne alles HTML aus den Posts. Da es bei mir nicht so viele waren, habe ich es einfach per Hand gemacht (nach ein paar schlauen Suchen und Ersetzen im ganzen Verzeichnis). Erstmal nur ganz grob – Feinarbeit folgt später.
Blog-Beiträge wollte ich dennoch ganz gerne in Markdown schreiben. Also alle Dateien in .md umbenannt, das HTML-Zeug rausgelöscht und alles ordentlich strukturiert. Dauert etwas und macht absolut keinen Spaß. Wenn man mehrere hundert Beiträge hat dreht man unter Garantie durch. Da würde ich mir fast die Arbeit machen und den Importer umschreiben, um möglichst nah an das Ergebnis zu kommen.
In meinem Fall waren es aber nur 21 Beiträge. Das ist zu verkraften. Trotzdem nicht schön…
Navigation
Das war für mich das anstrengendste Thema mit dem größten Anteil an Zeitverschwendung. Viel zu lange habe ich versucht, die Navigation dynamisch erstellen zu lassen. Lasst es am besten direkt sein. Ich bin nun dazu über gegangen, die komplette Navigation in eine yaml-Datei auszulagern und mit Jekyll zu laden. Das geht (dank entsprechender Data-Files) auch sehr einfach.
Hier die Datei im _data-Verzeichnis:
- title: Home
url: /
- title: Blog
url: /blog/
- title: Lösungen
url: /open-source-loesungen/
subnavigation:
- title: FHEM
url: /open-source-loesungen/fhem/
- title: Hardware
url: /hardware/
subnavigation:
- title: Raspberry Pi
url: /hardware/raspberry-pi/
- title: CUL
url: /hardware/cul-stick/
- title: Herstellerübersicht
url: /herstelleruebersicht/
- title: Protokolle
url: /protokolle-standards/
- title: Apps
url: /apps/
- title: Kontakt
url: /kontakt/
Und das passende HTML dazu:
<div class="collapse navbar-collapse navbar-header-collapse">
<ul class="nav navbar-nav navbar-right">
{% for p in site.data.navigation %}
<li class="dropdown">
<a class="dropdown-toggle" data-delay="50" {% if p.subnavigation %}data-hover="dropdown" data-toggle="dropdown"{% endif %} href="{{ p.url | prepend: site.baseurl | replace: '//', '/' }}">
<span>
{{ p.title }}
{% if p.subnavigation %}
<i class="fa fa-angle-down"></i>
{% endif %}
</span>
</a>
{% if p.subnavigation %}
<ul class="dropdown-menu" role="menu">
{% for s in p.subnavigation %}
<li class=" dropdown-submenu">
<a href="{{ s.url | prepend: site.baseurl | replace: '//', '/' }}">{{ s.title }}</a>
</li>
{% endfor %}
</ul>
{% endif %}
</li>
{% endfor %}
</ul>
</div>
Hier schaue ich also einfach immer, ob es Elemente unter Subnavigation gibt und hänge diese bei Bedarf an. Dank Bootstrap3-Theme wirklich leicht umzusetzen.
Gravatar
Der Dienst ist mir doch schon sehr ans Herz gewachsen. Hier habe ich ein sehr kurzes Snippet im Netz gefunden, um per Plugin die Autoren-Bilder von Gravatar zu laden.
require 'digest/md5'
module Jekyll
module GravatarFilter
def to_gravatar(input, size=165)
"//www.gravatar.com/avatar/#{hash(input)}?s=#{size}"
end
private :hash
def hash(email)
email_address = email ? email.downcase.strip : ''
Digest::MD5.hexdigest(email_address)
end
end
end
Liquid::Template.register_filter(Jekyll::GravatarFilter)
Meine Autoren-Daten habe ich in ein extra Include gepackt. Der entscheidene Teil sieht dabei so aus:
<img alt="{{ page.author.display_name }}" width="165" height="165" class="img-circle img-responsive center-block"
src="{{ page.author.email | to_gravatar }}"/>
Einfach, oder?
RSS-Feed
Der Feed ist zum Glück relativ schnell generiert. Dazu legt man sich eine feed.xml im root-Verzeichnis an und fügt folgenden Inhalt ein:
---
layout: null
---
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<title>{{ site.title | xml_escape }}</title>
<description>{{ site.description | xml_escape }}</description>
<link>{{ site.url }}{{ site.url }}/</link>
<atom:link href="{{ "/feed.xml" | prepend: site.baseurl | prepend: site.url }}" rel="self" type="application/rss+xml"/>
<pubDate>{{ site.time | date_to_rfc822 }}</pubDate>
<lastBuildDate>{{ site.time | date_to_rfc822 }}</lastBuildDate>
<generator>Jekyll v{{ jekyll.version }}</generator>
{% for doc in site.posts limit:100 %}
<item>
<title>{{ doc.title | xml_escape }}</title>
<description>{{ doc.content | xml_escape }}</description>
<pubDate>{{ doc.date | date_to_rfc822 }}</pubDate>
<link>{{ doc.url | prepend: site.feedurl }}</link>
<guid isPermaLink="true">{{ doc.url | prepend: site.feedurl }}</guid>
</item>
{% endfor %}
</channel>
</rss>
Fertig!
Amazon-Affiliate-Links
Zuvor hatte ich AmazonSimpleAdmin im Einsatz, was ich auch nicht mehr missen möchte. Automatisch Bilder einbetten und Preise abholen ist schon eine super Sache! Für dieses Thema habe ich mir ein Jekyll-Plugin gesucht und angepasst. Da das Thema in sich aber relativ umfangreich ist und interessiert sicherlich nicht jeden. Daher freut euch auf einen eigenen Blog-Beitrag zu dem Thema in Kürze.
Kommentare
Die Kommentare werden vom Importer als Array in jede Datei aufgenommen. Ist natürlich nicht sehr praktisch. Ich habe mich dafür entschieden auf Disqus umzusteigen und das Ganze unter jedem Post einzubinden. Falls man schon sehr viele Kommentare hat, gibt es ein WordPress-Plugin um diese zu exportieren und bei Disqus wieder hochzuladen – dann verliert man auch nichts. Da meine Seite aber die meiste Zeit brach lag, verwerfe ich die paar Kommentare einfach. Eine neue Seite kann man hier registrieren.
Danach nur noch ein JavaScript-Snippet in die Seite einbinden und fertig. Das war der leichteste Teil!
Fazit
Ich habe mir das Ganze sehr sehr viel einfacher vorgestellt. Anfangs dachte ich: „Hey cool, ein Migrations-Tool“. Von der Idee, alles importieren zu können, und sich am Ende nur noch um den Feinschliff zu kümmern, kann man sich aber schnell verabschieden. Selbst für meine kleine WordPress-Seite mit sehr sehr wenigen Posts hat es mich etliche Stunden gekostet. Je mehr Short-Codes man verwendet, desto schwieriger wird es. Möchte man exakt die gleiche Funktionalität erneut abbilden, muss man viel in Ruby nachprogrammieren.
Das Ganze eignet sich also mehr für neue Projekte, als für bestehende. Denn wer hat schon ausschließlich Text in seinen Beiträgen und Seiten? Das, was wirklich lange dauert, sind die Formatierungen der Unterseiten und das schreiben der Jekyll-Plugins. Gerade, wenn man (wie ich) noch nicht so viel Ahnung von Ruby hat kostet es doch einiges an Einarbeitungszeit.
Nichtsdestotrotz ist Jekyll ein enorm mächtiges Framework und eine tolle Alternative zum performancehungrigen WordPress. Gut, natürlich eher für statische Seiten. Möchte man einen Blog betreiben, sollten die Schreiber etwas technisch versiert sein. Ansonsten macht das keinen Sinn. Es existiert in dem Sinne eben kein Backend.
Aber genau das macht es unglaublich schnell (sind ja nur statische Seiten), flexibel und sicher. Was soll man hacken, wenn man kein PHP auf dem Server findet? Für Angreifer gibt es also null Chancen. Im Vergleich lässt die nächste größere Sicherheitslücke in WordPress sicher nicht lange auf sich warten.
Also: Gebt Jekyll eine Chance! Große Projekte wie Magento und GitHub tun dies auch! Es ist keine Nischentechnologie mehr. Sich wenigstens einmal kurz damit beschäftigen um das Prinzip zu verstehen lohnt sich auf jeden Fall. Und hinten raus spart man sicher eine Menge Zeit. Immerhin kann man sich direkt auf die Inhalte stürzen und muss sich nicht mit Updates und Performance-Problemen rumschlagen. Für sehr viele Probleme gibt es auch schon eine Lösung auf GitHub – die Community ist also sehr aktiv!
Zum Zeitpunkt dieses Beitrags ist die Seite noch nicht ganz fertig. Ich hoffe aber, dass die Arbeiten bald abschließen kann. Auf dem Weg werden mir sicher noch viele weitere Dinge auffallen. Dann folgen noch einzelne Beiträge.
Offene Themen
- Such-Funktion
- XML-Sitemap